bomonike
 We dynamically setup and scale AI apps running locally and within AWS, Azure, GCP, and other clouds, using free open-source software (Ray.io, Anyscale, PyTorch)
We dynamically setup and scale AI apps running locally and within AWS, Azure, GCP, and other clouds, using free open-source software (Ray.io, Anyscale, PyTorch)Overview
- Why Ray / Anyscale?
- Our project is to scale MCP servers:
- Dive in
- Marketing:
- Customers
- Ray.io by Anyscale hosted platform
- Anyscale leaders
- yaml file
- RayService for Observability
- Components
- Ray Core
- Ray’s AIR (AI Runtime)
- Ray Cluster
- Python Code Example
- Debugging and monitoring
- Competitors:
- Simulator
- Dataset Preprocessors
- Videos
- Books
- Agents
This article defines how you can run a large set of MCP servers serving lots of AI Agents in production mode.
The contribution of this article is use of CI/CD pipline that automates setup using Enterprise Anyscale (Ray.io) locally (on a MacMini) and within AWS, Azure, GCP, Digital Ocean, Hertzer (and other) clouds.
Why Ray / Anyscale?
Ray enables developers to run Python code at scale on Kubernetes clusters by abstracting orchestration on individual machines.
Workloads to use Ray for:
- Data processing (hosting MCP servers of AI Agents processing calendar & events)
-
Parallel processing Python code (using ray.remote)
- Reinforcement learning
- Distributed training
- Hyperparameter tuning
- Batch & Online inference, such as Requirements mangagement (Jira, Trello, Monday.com) planning
Ray is a high-performance distributed execution framework targets large-scale machine learning and reinforcement learning applications. Ray’s MLOps ecosystem includes features for:
- Developer tools
- Labeling
- Experiment tracking
- Model Registry
- Orchestration
- Monitoring
-
Feature Stores
- SSO / SAML is available on Ray & Anyscale
Anyscale.com is the company offering a paid edition of Ray built on top of Ray to provide:
-
RayTurbo: Anyscale’s optimized engine for Ray, delivering “5x” improved performance, Elastic Training, Zero-downtime rollouts, Multi-AZ, Replica compaction
- Interactive notebooks and workspaces
-
Seamless integrations
- Job Queues, Retries
- Multi Cloud & On Prem support
- Workspace (VSCode IDE running on cluster head node)
- High Availability Services (such as setup GCS w/Redis)
Enterprise governance and security:
- Quota Management
- Data Encryption
- Access Controls
- Usage Tracking
- Audit Logs
Observability & Monitoring: https://docs.anyscale.com/monitoring/tracing/ (OTel integration)
- Persistent Logs
- Export logs to Datadog, CloudWatch
- Alerting
- Unified Log Viewer
- Tracing from Pofiler
- Distributed Debugger
Our project is to scale MCP servers:
- https://www.perplexity.ai/search/how-is-mcp-scaled-across-many-E2FBFN9CSGutRwn3YafkFw#0
- https://www.arsturn.com/blog/mcp-server-strategies-effective-methods-for-scaling-up
- Advice such as “start simple” is plain wrong with scaling: https://www.reddit.com/r/mcp/comments/1k9knt9/how_are_teams_deploying_mcp_servers_for/?rdt=61954
Dive in
- Signup at ray.io
- Take the Intro to Ray
by Max (author of OReilly book “Ray: A Distributed Computing Framework for Python”).
- Project code is at https://github.com/ray-project/ray and https://github.com/ray-project/ray-docker
-
Anyscale provides free tutorial and free certification (just 10 questions)
- Setup our own Ray.io instance locally on Wilson’s MacMini.
- Install MCP with agents within our local Ray.io instance.
- Anthropic Reference MCP
- Azure MCP https://github.com/Azure/azure-mcp?tab=readme-ov-file
-
Setup in cloud Digital Ocean or Hetzner.
- What useful app? __ written in Python in Docker image
- https://res.cloudinary.com/dcajqrroq/image/upload/v1716481274/odoo-docker-officialapps-240522_tkt77p.png
- Calendaring AI - what are available?
- For Provost office to scour market trends - YouTube video about coding univ camps
Marketing:
- Blog for Anyscale as Partners/resellers
- Blog for MCP
- Article - LinkedIn, DEv.to, Medium
- YouTube video
- Udemy
- Market to colleges
Customers
Customer cases studies:
-
VIDEO: 31:38 Distributed training with Ray on Kubernetes at Lyft
-
BLOG: Uber’s Journey to Ray on Kubernetes: Ray Setup
Ray.io by Anyscale hosted platform
Ray was first developed in 2016 by UC Berkeley’s RISELab (the successor to the AMPLab that created Apache Spark and Mesos). Thir code is now open-sourced (with 36.8k stars) at:
- https://github.com/ray-project/ray
"Ray is an AI compute engine. Ray consists of a core distributed runtime and a set of AI Libraries for accelerating ML workloads." The most active contributor is Anyscale employee (since Sep 2024) Srinath Krishnamachari, who also created https://github.com/srinathk10/ray_mac_dev
Anyscale leaders
https://www.glassdoor.com/Reviews/Anyscale-CA-Reviews-E3377996.htm rates 4.8/5 stars among 100 employees. Employer pays 99% of health insurance premiums but does not match 401k.
100% approve of CEO Keerti Melkote who joined in July 2024 after being CTO & CEO of Aruba Networks thru to purchase by HPE.
Since 2019, Ion Stonica is co-founder of Ray and the Professor of Electrical Engineering and Computer Science at University of California, Berkeley, after being a CEO & co-founder at Databricks in 2013. VIDEO
https://www.linkedin.com/company/joinanyscale/posts/?feedView=all
https://www.builtinsf.com/company/anyscale at 415-267-9902, SOMA neighborhood: 55 Hawthorne St 9th Floor, San Francisco, CA 94105 Map (across the street from 3-Michelin star Asian restaurant BenuSF.com)
yaml file
VIDEO “Getting Started with Ray Clusters” by Saturn Cloud Mar 2, 2023 shows setup within AWS.
KubeRay
The KubeRay project (https://ray-project.github.io/kuberay/) is used to deploy (and manage) Ray clusters on Kubernetes. KubeRay packages key Ray components into “pods.” From https://bit.ly/ray-arch:
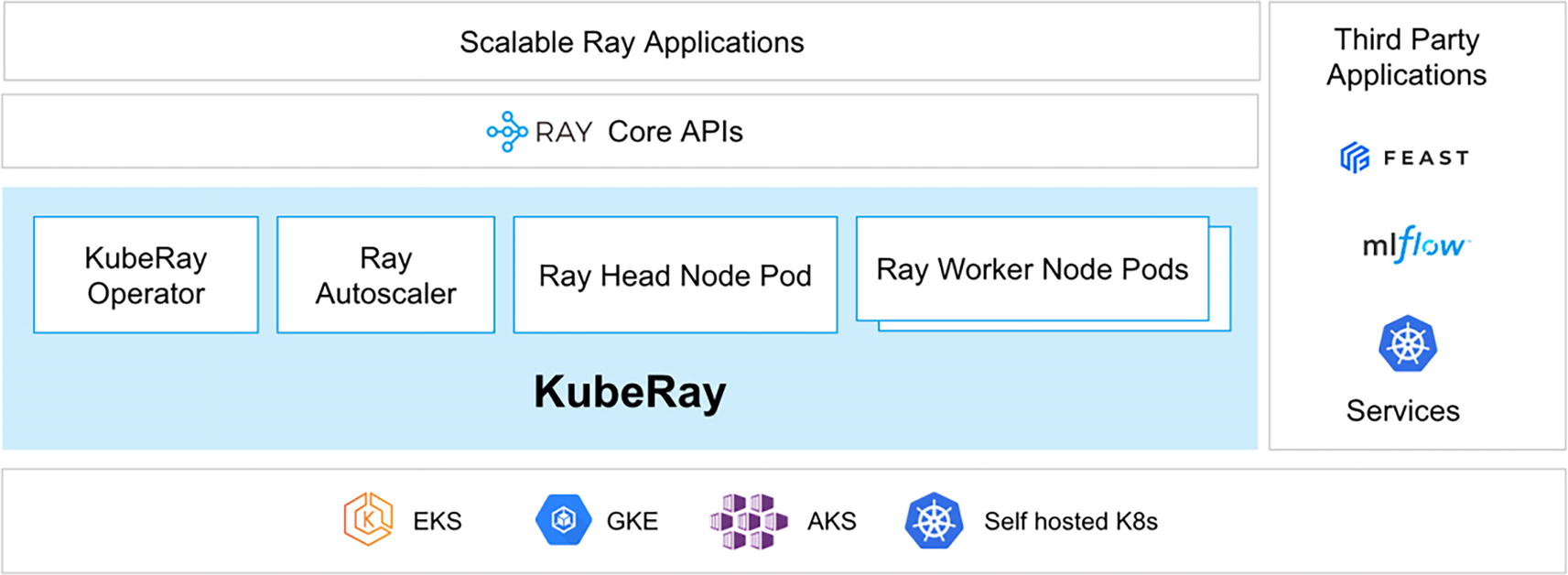
A central component of KubeRay is the “KubeRay Operator” responsible for starting and maintaining the lifetime of other Ray pods – headnode pod, worker node pods, and the autoscaler pod (responsible for increasing or decreasing the size of the cluster). In particular, for online serving/service scenarios (which is becoming more popular now), the KubeRay operator is responsible for making sure the Ray Headnode pod is highly available.
RayService for Observability
In KubeRay, creating a RayService will first create a RayCluster and then create Ray Serve applications once the RayCluster is ready.
RayService is a Custom Resource Definition (CRD) designed for Ray Serve.
https://docs.ray.io/en/latest/cluster/kubernetes/troubleshooting/rayservice-troubleshooting.html#observability
Metrics - Logs - Traces - Dashboard - Triggers - Alerts
Components
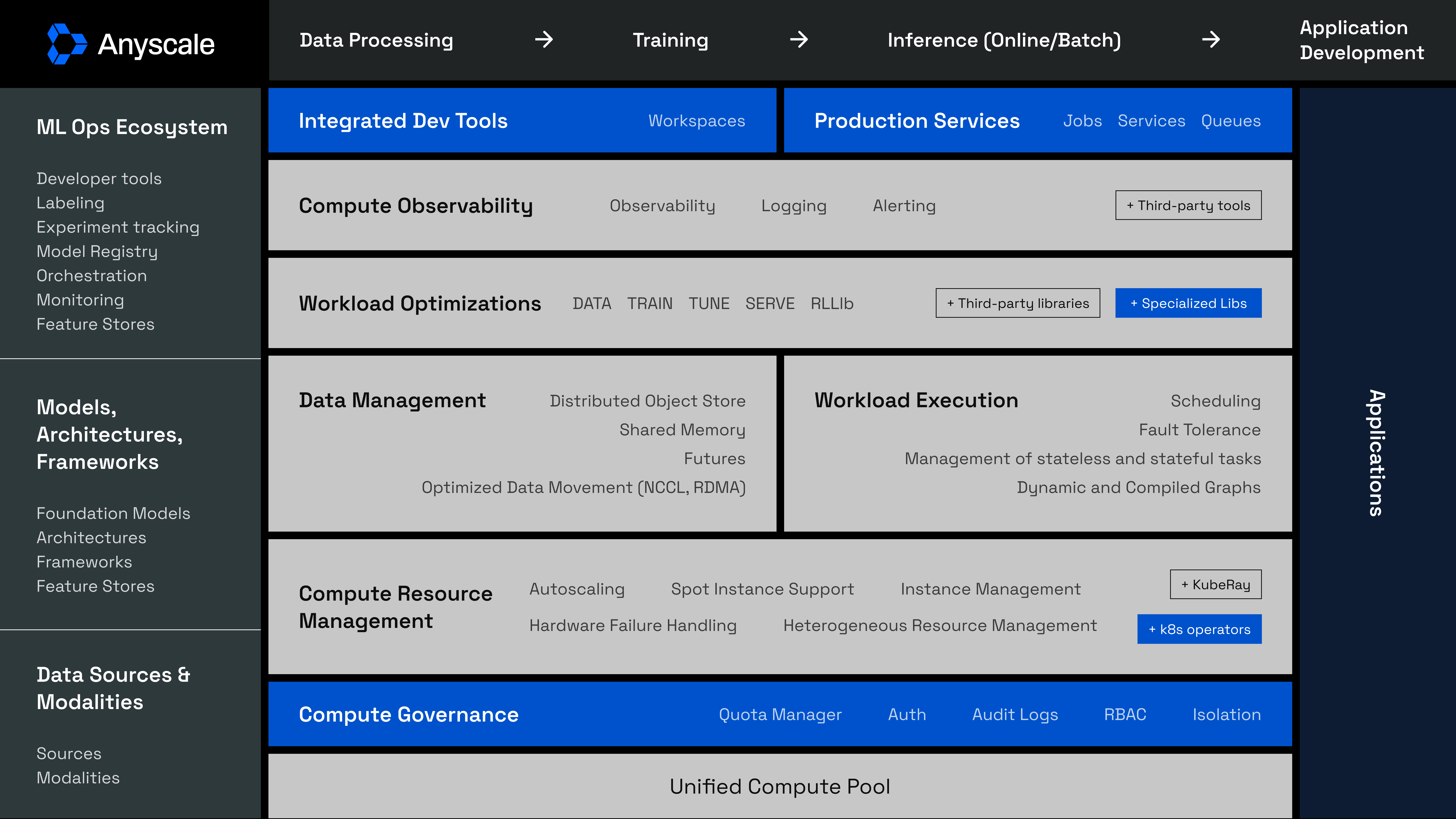
Compute Observability
Metrics are reported during training using ray.train.report NOT after every epoch.
The purpose of the Ray take batch method in Ray’s Dataset API is retrieves a specified number of rows from a distributed dataset as a single batch.
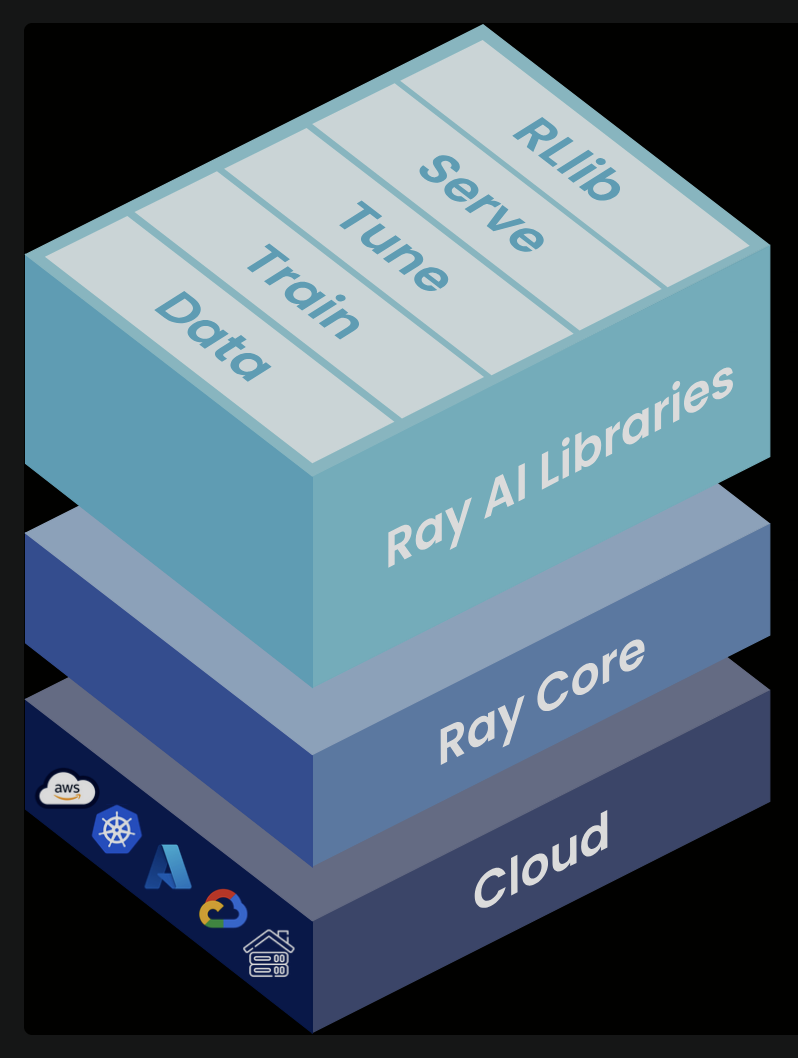
Ray Core
Ray Core Quickstart is a general-purpose framework to scale out Python apps with distributed parallelism. Ray Core provides asynchronous/concurrent program execution on a cluster scale, by spanning multiple machines and heterogeneous computing devices, but abstracted away from developers.
The basic application concepts a developer should understand in order to develop and use Ray programs:
-
Driver: The program root, or the “main” program. This is the code that runs “ray.init()”.
-
Object: An application value. These are values that are returned by a Task/Actor, or created through “ray.put”. Objects are immutable: they cannot be modified once created. A worker can refer to an object using an “ObjectRef.”
-
Task: A remote function invocation. This is a single function invocation that executes on a process different from the caller, and potentially on a different machine. A task can be stateless (a “@ray.remote” function) or stateful (a method of a “@ray.remote” class – see Actor below). A task is executed asynchronously with the caller: the “.remote()” call immediately returns one or more “ObjectRefs” (futures) that can be used to retrieve the return value(s).
-
Actor: A stateful worker process (an instance of a “@ray.remote” class). Actor tasks must be submitted with a handle, or a Python reference to a specific instance of an actor, and can modify the actor’s internal state during execution.
-
Job: The collection of tasks, objects, and actors originating (recursively) from the same driver, and their runtime environment. There is a 1:1 mapping between drivers and jobs.
Ray’s AIR (AI Runtime)
Built on top of Ray Core, Ray’s AI libraries Quikstart target Workload Optimization. By order of usage during dev lifecycle) scales ML workloads:
https://github.com/ray-project/ray-educational-materials/blob/main/Introductory_modules/Quickstart_with_Ray_AIR_Colab.ipynb
-
INTRO: Ray Data (Loading) - Ingest and transform raw data; perform batch inference by mapping the checkpointed model to batches of data. To load images from a file-based datasource:
dataset = ray.data.read_parquet( "s3://anyscale-training-data/intro-to-ray-air/nyc_taxi_2021.parquet" )-
INTRO: Ray Train and RLib (Reinforcement Learning library) - use Trainer to scale XGBoost model training
-
RaySGD (Stochastic Gradient Descent) to train Machine Learning?
-
INTRO: Ray Tune - use Tuner to scale HyperParameter Optimization (HPO) tuning. The train_my_model(config: dict[str,Any]) function signature is expected for the Ray Tune training. __ search algorithm is the default used for hyperperameter tuning.
-
INTRO: Ray Serve - Deploy the model to serve online inference (as HTTP servers). Ray Serve can HTTP routing and OpenAPI docs @serve.ingress FastAPI feature to integrate. Percentages in the resource allocation can specify fractional compute resources for a deployment replica. Request consolidation is not a feature.
-
Community Integrations?
-
The ScalingConfig utility is used to configure the number of training workers in a Trainer or Tuner.
The ResNet neural network model is used in the PyTorch implementation of the MNIST Classifer.
Sample Code Programming Ray
Ray is a distributed execution framework to scale Python applications.
pip install 'ray[default]'
! pip install -U ray==2.3.0 xgboost_ray==0.1.18
So Ray is “invasive”. Once Ray is used, you’re all in.
Ray is coded as a wrapper around app functions implemented in C++ and Python:
- @ray.init() - Initialize the “Ray context” runtime and makes sure the current process is connected to a Ray Cluster.
- @ray.remote - Decorates functions/classes so they become Ray Tasks and Actors to be executed on a cluster (as distributed units)
- @ray.remote() - Postfix to trigger the asynchronous execution of remote function calls and class instantiations
- ray.put(x) - store Python object x in Ray object store and makes sure the object can be accessed by other Ray Tasks and Actors
- ray.get(y) - retrieve results from remote tasks. Blocking call that waits for the Python object to be resolved. If y involves a function call, ray.get() will block until the execution of the function itself, and all other required function calls to finish. Instead, if y was earlier stored in Ray object store ray.get() will block until the Python object is retrived from the Ray object store.
Ray Cluster
In the diagram from this VIDEO:
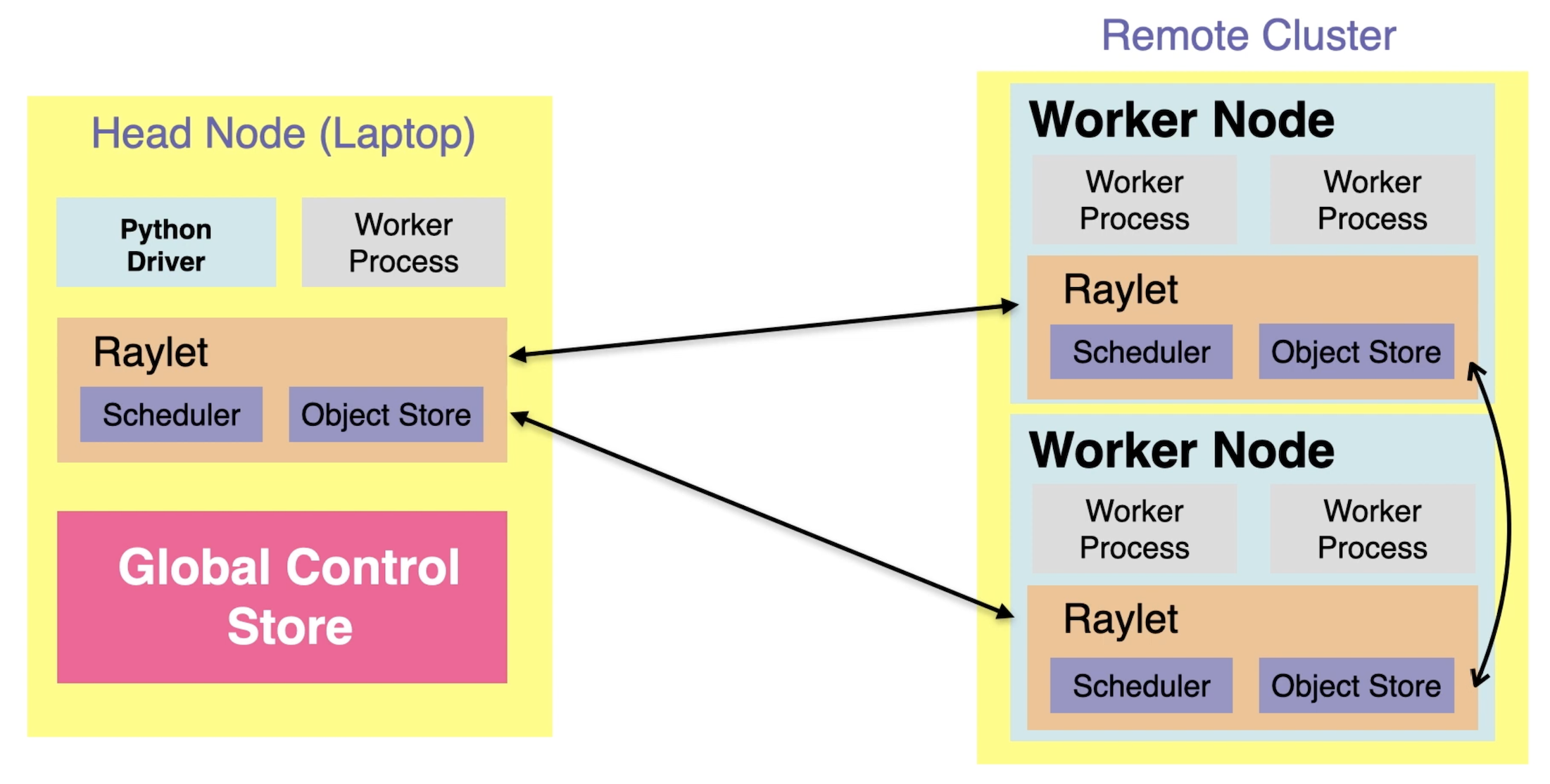
Obserability would involve these metrics displayed over time in dashboards:
- The number of Remote Clusters in each server
- The count of Worker Processes in each Head Node, Remote Cluster, and Remote Worker Node
- The memory used by Worker Processes Head Nodes, Remote Clusters, and Remote Worker Nodes
- The tasks and actors in each Scheduler within each Raylet
- The number of objects in each Object Store
- The rate of churn of objects in each Object Store
- The span of time between Raylets communicating
- The number of Worker Processes within each Worker Node
- Global Control Store (GCS)
Python Code Example
Here’s a Basic Ray Task Example in Python, using Ray.io for distributed computing, incorporating key concepts from the documentation:
import time # and other standard libraries
import ray
# Initialize Ray runtime (automatically uses available cores):
ray.init(num_cpus=4)
# Convert function to distributed task:
@ray.remote(num_cpus=2, num_gpus=0)
def process_data(item):
time.sleep(item / 10) # Simulate work
return f"Processed {item}"
# Launch parallel tasks
results = ray.get([process_data.remote(i) for i in range(5)])
print(results)
# Output: ['Processed 0', 'Processed 1', 'Processed 2', 'Processed 3', 'Processed 4']
Actor Pattern Example: Usage:
tracker = DataTracker.remote()
ray.get([tracker.increment.remote() for _ in range(10)])
print(ray.get(tracker.get_count.remote())) # Output: 10
@ray.remote
class DataTracker:
def __init__(self):
self.count = 0
def increment(self):
self.count += 1
def get_count(self):
return self.count
Advanced Pattern (Data Sharing)
# Store large data in shared memory:
data_ref = ray.put(list(range(1000)))
@ray.remote
def process_chunk(ref, start, end):
data = ray.get(ref)
return sum(data[start:end])
# Process chunks in parallel:
results = ray.get([
process_chunk.remote(data_ref, i*100, (i+1)*100)
for i in range(10)
])
print(sum(results)) # Sum of all chunks
For cluster deployment, add ray.init(address=’auto’) to connect to existing clusters. The examples demonstrate task parallelism, stateful actors, and data sharing - fundamental patterns for distributed computing with Ray.
https://courses.anyscale.com/courses/take/intro-to-ray/lessons/60941259-introduction-to-ray-serve
VIDEO: Create Docker file for Python program
Debugging and monitoring
Ray Cloud Quickstart enables use of GPUs being managed as clusters of containers managed by Kubernetes.
“Ray meets the needs of ML/AI applications—without requiring the skills and DevOps effort typically required for distributed computing.
- anyscale.com/academy written by Dean Wampler
- https://docs.ray.io/en/latest/ray-overview/getting-started.html
- https://docs.ray.io/en/latest/ray-core/examples/overview.html
Social
- ray-distributed.slack.com
- anyscale.com/events
-
raysummit.org
-
online and in-person Ray Summit conferences (http://raysummit.org), speaking at and sponsoring other conferences, tutorial development, webinars, blog posts, advertising, etc.
- https://www.upwork.com/services/search?nbs=1&q=anyscale
Anyscale People
On video October 5 2020 Dean Wampler (deanwampler.com) when he was Head of DevRel at Anyscale, said “The biggest use uer of Ray is Ant Financial in China. It’s like the Stripe/Paypal of China, running thousands of nodes.” He’s now IBM’s chief technical representative to the AI Alliance (@the-aialliance). * Author of “Programming Scala, Third Edition”, 2021 * polyglotprogramming.com/talks
Jules Damji, formerly at Databrickss, is Lead Developer Advocate at Anyscale, gave these talks:
- https://github.com/dmatrix/ray-core-tutorial#-setup-instructions-for-local-laptop-
- https://github.com/dmatrix/ray-misc-examples
- https://github.com/ray-project/ray-educational-materials
- Feb 16, 2022 VIDEO “Ray: A Framework for Scaling and Distributing Python & ML Applications”
- VIDEO “Introduction to Ray for distributed and machine learning applications in Python”
Competitors:
- Apache Spark VIDEO
- Palantir
- DaSC distributed arrays - visualization of its direct-to-disk piece and click graph
- MXNet (now Apache TVM)
- NVIDIA
- ex Facebook
Simulator
Dataset Preprocessors
The Ray Data library provides preprocessors, scalers, and encoders:
- Generic preprocessors: Concatenator, Preprocessor, SimpleImputer
- Feature scalers: MaxAbsScaler, MinMaxScaler, Normalizer, PowerTransformer, RobustScaler, StandardScaler
- Categorical encoders: Categorizer, LabelEncoder, OneHotEncoder, MultiHotEncoder, OrdinalEndcoder
A custom preprocessor to output transformed datasets:
import ray
from ray.data.preprocessors import MinMaxScaler
ds = ray.data.range(10)
preprocessor = MinMaxScaler(["id"])
ds_transformed = preprocessor.fit_transform(ds)
print(ds_transformed.take())
Videos
Jonathan Dinu has several videos (until 2021) on the University of Jonathan channel:
- Ray: A Framework for Scaling and Distributing Python & ML Applications
- https://github.com/jonathandinu/spark-ray-data-science running on Juypter
-
Spark, Ray, and Python for Scalable Data Science Pearson Live Lessons June 2021 7.5 Hours of Video Instruction Conceptual overviews and code-along sessions get you scaling up your data science projects using Spark, Ray, and Python. Overview Machine learning is moving from futuristic AI projects to data analysis on your desk. You need to go beyond following along in discussions to coding machine learning tasks. Spark, Ray, and Python for Scalable Data Science LiveLessons show you how to scale machine learning and artificial intelligence projects using Python, Spark, and Ray.
docker run -p 8888:8888 -p 8265:8265 -p 8000:8000 -p 8089:8089 -v $(pwd):/home/jovyan/ –pull ‘always’ psychothan/scaling-data-science
Books
- BOOK: MLOps with Ray: Best Practices and Strategies for Adopting Machine Learning Operations
342 pages Apress June 2024
By Hien Luu, Max Pumperla and Zhe Zhang
“Understand how to use MLOps as an engineering discipline to help with the challenges of bringing machine learning models to production quickly and consistently. This book will help companies worldwide to adopt and incorporate machine learning into their processes and products to improve their competitiveness. The book delves into this engineering discipline’s aspects and components and explores best practices and case studies.
- Introduction to MLOps
- MLOps Adoption Strategies and Case Studies
- Feature Engineering Infrastructure
- Model Training Infrastructure
- Model Serving Infrastructure
- ML Observability Infrastructure
- Ray Core
- An Introduction to the Ray AI Libraries
- The Future of MLOps
-
BOOK: Scaling Python with Ray” 266 pages November 2022 O’Reilly Media, Inc. By Holden Karau and Boris Lublinsky Serverless computing enables developers to concentrate solely on their applications rather than worry about where they’ve been deployed. With the Ray general-purpose serverless implementation in Python, programmers and data scientists can hide servers, implement stateful applications, support direct communication between tasks, and access hardware accelerators. In this book, experienced software architecture practitioners Holden Karau and Boris Lublinsky show you how to scale existing Python applications and pipelines, allowing you to stay in the Python ecosystem while reducing single points of failure and manual scheduling.
-
https://learning.oreilly.com/library/view/-/9781633437203/ LLMs in Production
-
BOOK: Learning Ray 271 pages O’Reilly Media, Inc. February 2023 By Max Pumperla, Edward Oakes and Richard Liaw “Get started with Ray, the open source distributed computing framework that simplifies the process of scaling compute-intensive Python workloads. With this practical book, Python programmers, data engineers, and data scientists will learn how to leverage Ray locally and spin up compute clusters. You’ll be able to use Ray to structure and run machine learning programs at scale. Authors Max Pumperla, Edward Oakes, and Richard Liaw show you how to build machine learning applications with Ray.
-
BOOK: What Is Ray? 46 pages O’Reilly Media, Inc. September 2020 By Dean Wampler “Dean Wampler from Anyscale introduces you to Ray, an open source project that provides a concise and intuitive Python API for defining tasks that need to be distributed. Built by researchers at UC Berkeley, Ray does most of the tedious work of running workloads at massive scale. For the majority of distributed workloads, this guide shows you how Ray provides a flexible, efficient, and intuitive way to get work done.”
-
Ownership: A Distributed Futures System for Fine-Grained Tasks. In NSDI (pp. 671-686). by Wang, S., Liang, E., Oakes, E., Hindman, B., Luan, F.S., Cheng, A. and Stoica, I., 2021, April.
-
In reference to RPC: it’s time to add distributed memory. In HotOS (pp. 191-198). By Wang, S., Hindman, B. and Stoica, I., 2021, June.
- Ray v2 Architecture (https://bit.ly/ray-arch) by Ray Team, October 2022
Agents
https://youtube.com/shorts/svm_uGBeIm0?si=MfN9c9qaJT74utZs
https://www.youtube.com/watch?v=IfjGP9jIaQ0 Ray AIR Robert Demo 2022